OPC Studio User's Guide and Reference
Data Provision And Consumption Models
By "data provision", we understand the process through which your code provides data for OPC reads and subscriptions required by OPC clients.
By "data consumption", we understand the process through which your code consumes the data from OPC clients in OPC write operations.
The OPC Wizard has two major models that you can use when providing data:
The data provision models can be combined in the same server, i.e. some data variables may use one model, and other data variables a different model.
There is no explicit "switch" to choose between the two models. With great simplification, we can say that if you specify a read method for the Pull Data Provision Model, this model will be used. If you do not specify the read method, you then need to write the code to gather and push the data, and you end up with the Push Data Provision Model. Here is (roughly) what happens when the OPC Wizard handles the OPC Read request (or subscription update):
The code for pulling the data can be attached to each data variable separately, or you can use a common code on some higher level in the tree of the server nodes - for example, a folder can have code that handles all Reads for the data variables contained in the folder. For more details, see Request Propagation (Bubbling).
OPC clients can receive the data from OPC server in two ways: Either by making an explicit Read calls at the time they choose, or by subscribing to changes of the data. With a subscription, the OPC server sends the data to the OPC client when a specified criteria is fulfilled - in the common case, when the value changes. The subscription mechanism is crucial in OPC communications, because it is both more efficient that repeated Reads, and it can also guarantee that no significant data change is missed.
Each data subscription has a sampling interval associated with it. The sampling interval determines how often the data should be obtained from the underlying source. It is possible that multiple data subscriptions are made to the same data variable.
Providing data for data subscriptions is considered part of data provision model. In the simple case, the OPC Wizard allows the data subscriptions be implemented without further coding effort. It keep track of the data subscriptions to the data variable, and it also determines the shortest sampling interval currently requested by the OPC client data subscriptions (it is kept in the SamplingInterval Property). The OPC Wizard then periodically acquires the data needed for data subscription updates, using the same mechanism described in Data Provision Basics, i.e. using the Pull Data Provision Model or Push Data Provision Model, without any extra coding needed. This mode is called (subscription) Data Polling.
In some cases, however, the above described default behavior might be sub-optimal. This typically happens when the underlying data source already has some kind of subscription mechanism, and you would like to use it for performance and data accuracy reasons. OPC Wizard allows you to override the data subscription behavior, and replace it by your own. See Custom Data Subscriptions for details of this approach.
The OPC Wizard also has two major models that you can use use when consuming data:
The data consumption models can be combined in the same server, i.e. some data variables may use one model, and other data variables a different model.
There is no explicit "switch" to choose between the two models. With great simplification, we can say that if you specify a write method for the Push Data Consumption Model, this model will be used. If you do not specify the write method, you then need to write the code that pull the data from the data variable(s) and sends it to the underlying system, and you end up with Pull Data Consumption Model. Here is (roughly) what happens when the OPC Wizard handles the OPC Write request:
The code for handling the data push can be attached to each data variable separately, or you can use a common code on some higher level in the tree of the server nodes - for example, a folder can have code that handles all Writes for the data variables contained in the folder. For more details, see Request Propagation (Bubbling).
When the WriteLoopback Property of the data variable is true (the default), any data successfully written to the data variable will also update its ReadAttributeData Property, and will therefore become the read data for subsequent operations (mainly in Push Data Provision Model). You can set the WriteLoopback Property of the data variable to false to disable this behavior.
The write loopback also allows the implementation of Read-Write Register Data Variables.
In many OPC servers, there are data variables (or groups of data variables) that have basically the same behavior, and differ just in the concrete "details" such as the target data item they represent, or their data type. Obviously your code define the behavior of each such data variable independently, and it will work well. It is, however, often the case that a shorted and more legible code can be achieved by defining the behavior of such nodes all at once. This is especially the case when the server nodes are organized logically in such a way that data variables that share some common characteristics reside in common parent (or generally ancestor) folder. It would then make sense to put the code that defines the data variable behavior on the parent (ancestor) folder level.
The request bubbling is a form of request propagation. It is a feature of OPC Wizard that allows you to place the code that define the data variable behavior or either the data variable level, or on any of its ancestors, up to the standard Objects folder, or even on the EasyUAServer Class instance.
With request bubbling, the Read or Write attempt is first made on the data variable itself. If it is handled, no further request propagation takes place. If it is not handled, the request is sent to the parent node (data variable or folder), and so on. If/when the request bubbling reaches the Objects folder and is still not handled, the request bubbles to the EasyUAServer.
For Reads (data provision), the "requests" we are referring to are the invocations of the OnRead Method and the eventual raising of the Read Event. For Writes (data consumption), the "requests" we are referring to are the invocations of the OnWrite Method and the eventual raising of the Write Event. There are also other, less commonly used requests that propagate in the same way.
The request propagation mechanism can be further controlled by certain properties on each server node. They are:
Request bubbling is illustrated on the picture below.
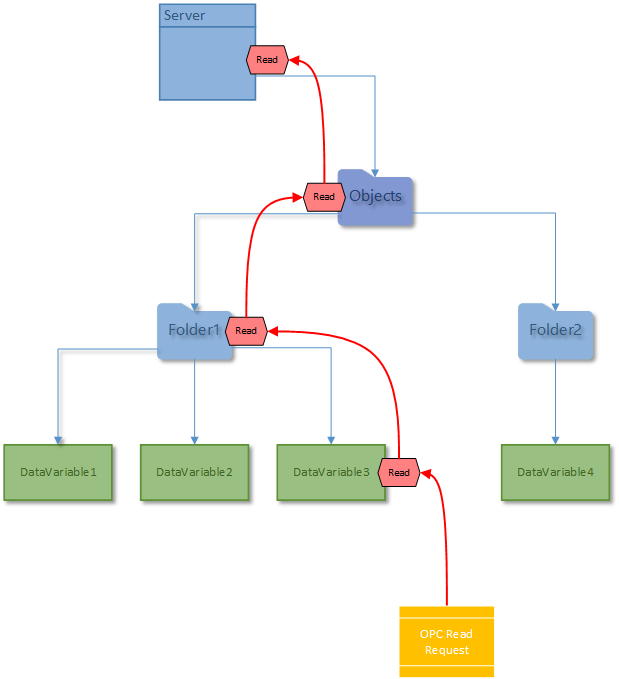
The picture shows a Read request on the data variable DataVariable3. Unless it is handled or terminated on this data variable, the request bubbles to its parent folder, Folder1. Unless it is handled or terminated there, it further bubbles to its parent, which is the standard Objects folder. Furthermore, unless the request is handled or terminated there, it finally bubbles to the server object (the EasyUAServer Class instance). The code that handles the Read request can therefore be written specifically e.g. on DataVariable3, or you can have more generic code that handles multiple data variables at once, and place the code (and handle the Read request) e.g. on the Folder1 level.
When you define a Read or Write (or other) behavior, you have two options:
The end result of both these options is about the same.
Handling the events is somewhat less efficient. Also, your code needs to add the event handler to each server node that requires it. Defining a derived class and overriding a method requires more coding, but it allows you to centralize the behavior of certain group of server nodes in that class, possibly with other related data or code.
Example: Examples - Server OPC UA - Implement variable reading on folder level, with inheritance
Example: Examples - Server OPC UA - Implement variable writing on folder level, with inheritance
The following sequence of steps describes in detail what happens when the data variable value is read by OPC Wizard.
If this sounds too complicated, let's try to put it into more comprehensible terms, although not that precise:
With this, you can see the flexibility provided by the algorithm used. It allows for various data provision approaches, and specifically:
The following sequence of steps describes in detail what happens when the data variable value is written by OPC Wizard.
If this sounds too complicated, let's try to put it into more comprehensible terms, although not that precise:
With this, you can see the flexibility provided by the algorithm used. It allows for various data consumption approaches, and specifically: